

Analysing Conversations on AI – Using AI!
What do people talk about when they talk about AI?

📌A note from the editors: the previous version of this post cut off the end of David’s article — in our opinion, the best part. Apologies for that and for re-sending📌
The more discerning regular readers of The Computational Philosopher may already be familiar with Conversations on AI. This workshop series brings together people from industry, academia, and wider society to discuss some of the most important questions around artificial intelligence. That mix is part of what makes it so interesting: these are not narrowly technical discussions, but live, multi-perspectival conversations. I was fortunate to be given access to transcripts of five past events, alongside the five podcast episodes (hosted by Armin Razavi and Stella Maude) that have aired so far.
The natural question is: what happens when you point the AI tools of computational text analysis at conversations about AI? Each technique gives us a different kind of map (a compressed representation) of the conversations. None of them tells the whole story. But together, they start to reveal patterns that would be hard to spot by reading alone.
The Corpus
The dataset included five live workshops, focused around the role of AI in different areas:
Creativity: How should humans co-create with AI?
Education: What does responsible education look like in the age of AI?
Innovation: How can we use AI to innovate for human benefit?
Investment: How should shareholders balance return and responsibility when investing in AI?
Health Sciences: How do we ensure human wellbeing is at the core of AI development in Health Sciences?
And five podcast episodes, hosted by Armin Razavi and Stella Maude:
Introductory podcast, with Annabel Gillard, Brian Ball, and Tracy Woods
The Future of Work, with Alysha Adams and Professor Chris Cowton
AI Governance, with Su Cizem
Poetry Special, with Aneira Roose-McClew, Yasmin Liverpool, and Louise-Anne De Belen
AI in Healthcare, with Tudor Toma
Which words stand out?
My first lens is to simply see which words are most prominent in each event. To do this, I used a formula called TF-IDF (term frequency-inverse document frequency). This scores words based on how prominent they appeared in any given event, compared to all the others.
Let’s look at the highest-scoring TF-IDF words for the events:



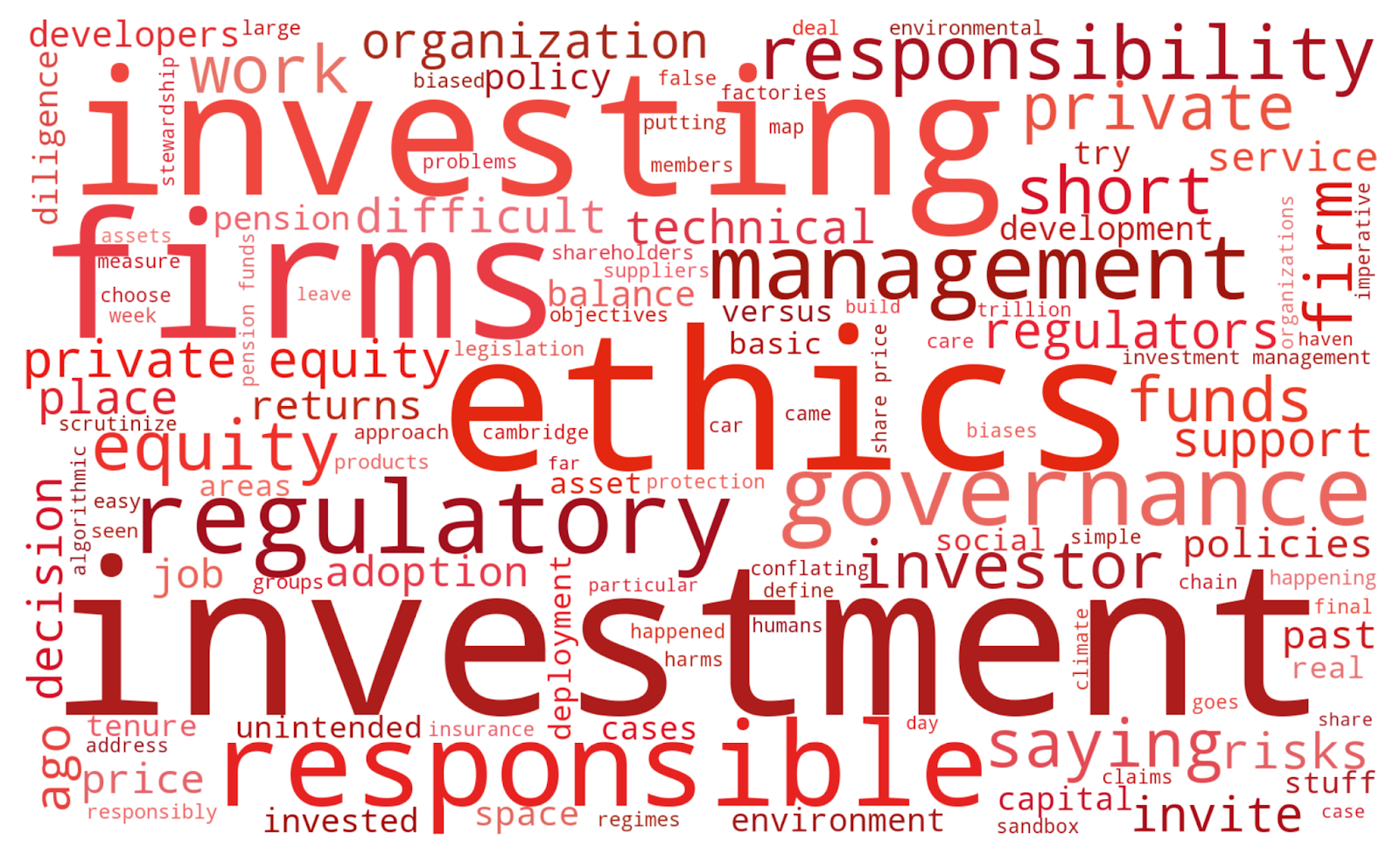
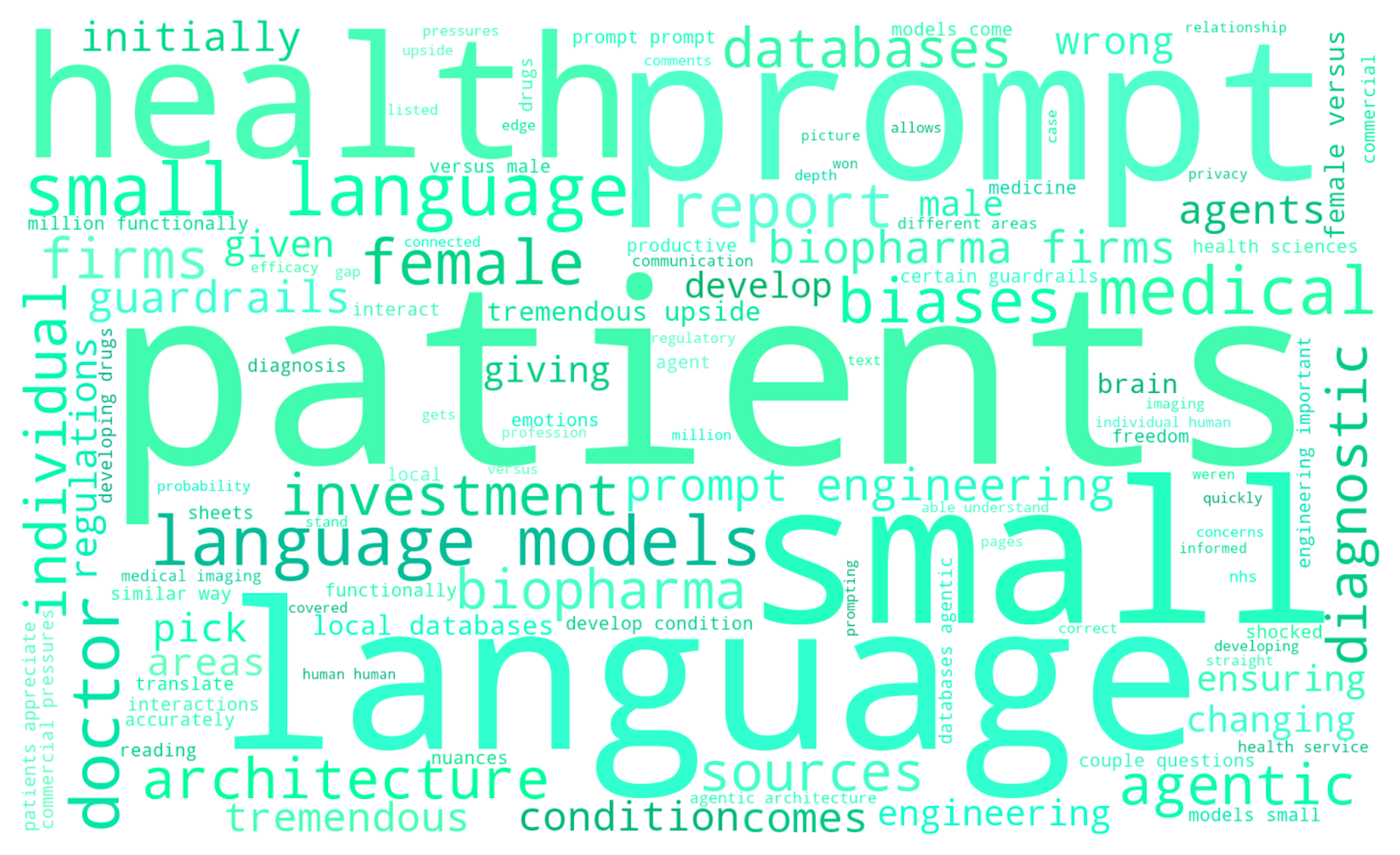
And for the podcasts:

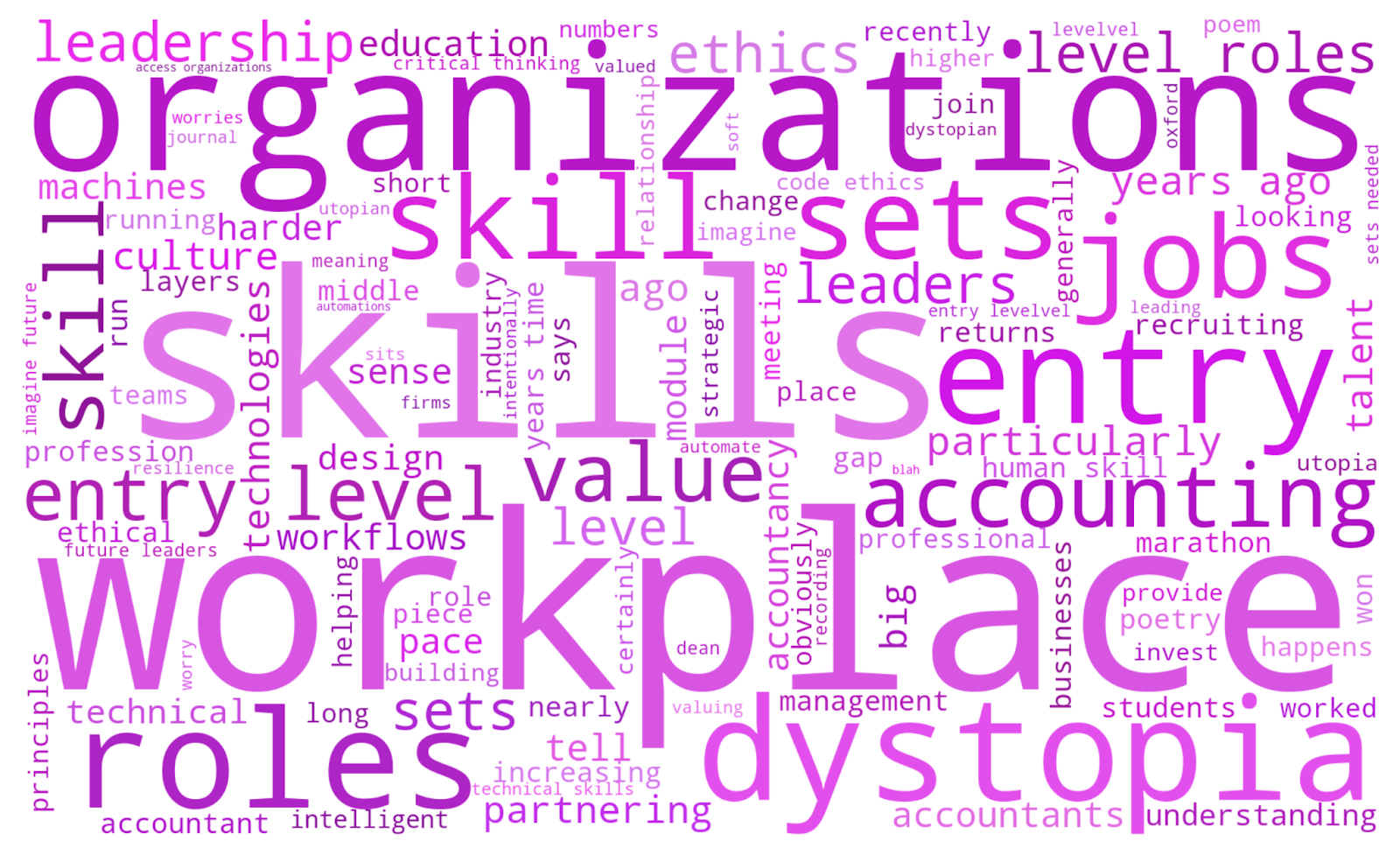


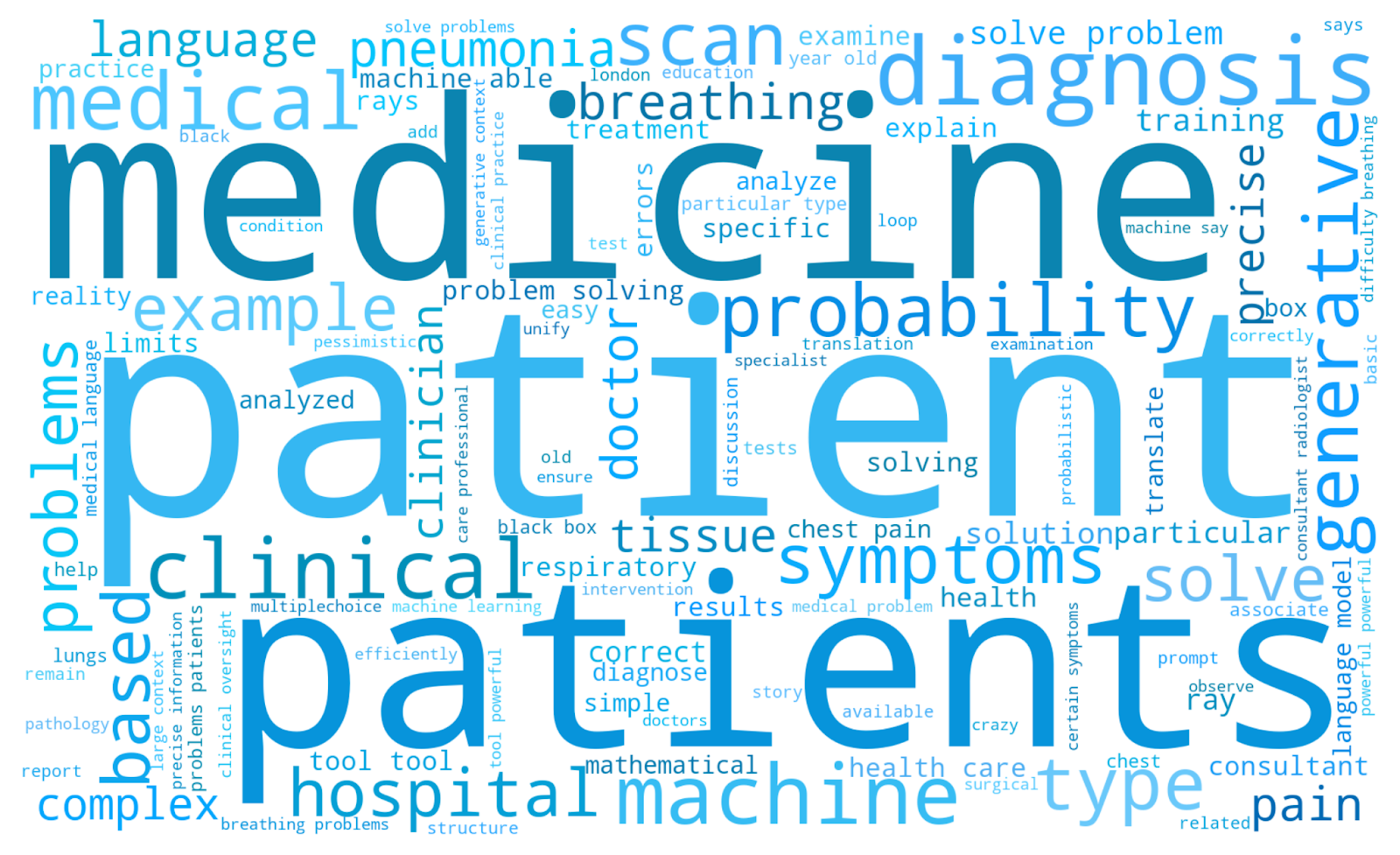
Many of the most prominent words are exactly what we would expect: “education” and “teachers” dominate the Education Event, “investment” and “firms” headline the Investment Event, “patient” and “medicine” lead the Healthcare Podcast. But there are some more intriguing findings too. “Ethics” looms large in the Investment Event, whilst “critical thinking” features prominently in the Education Event. We might have expected “humanity” to appear in the Poetry Podcast, but “human,” “humans,” and “values” dominate the Innovation Event as well! It seems reassuring that ethics, humans, values, and critical thinking are all central in these conversations about the role of AI.
What’s the tone of the Conversation?
Next, I used sentiment analysis to track the tone of the conversations, deploying a toolkit called VADER (Valence Aware Dictionary and sEntiment Reasoner). It assigns a compound sentiment score to each chunk of text, which I then average across each transcript. VADER is a relatively blunt instrument: it counts positive and negative words and applies some simple heuristic rules, but it can be useful as a broad directional indicator, when interpreted carefully!
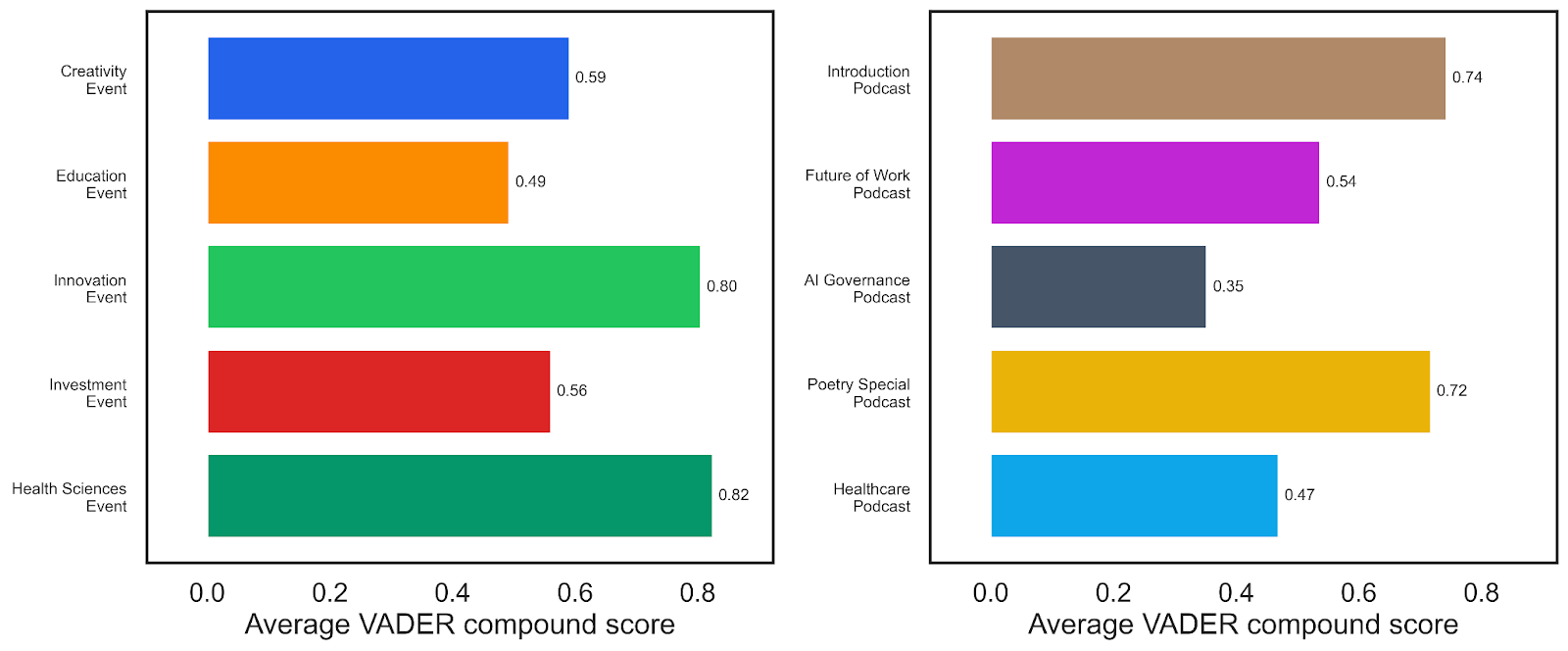
Positive scores (up to +1) indicate a positive sentiment, whilst negative scores (down to -1) suggest a negative affect. Fortunately, every single event and podcast seemed to show a positive sentiment! The Health Sciences Event scored highest among the events (0.82), closely followed by the Innovation Event (0.80). Among the podcasts, the Introduction Podcast (0.74) and the Poetry Special (0.72) led the way.
It’s worth pausing on what these numbers do and don’t mean. A high positive score doesn’t necessarily mean the conversation was cheerful or uncritical; it often reflects the use of aspirational, solution-oriented language. For example, the fact that the AI Governance Podcast scores lowest makes intuitive sense: discussions of systemic risk, red lines, and regulation tend to use more cautious and hedging language, which VADER reads as less positive. Sentiment scores are a useful rough compass, but they shouldn’t be mistaken for a quality judgement.
What are we talking about?
Next, let’s turn to topic modelling, specifically Non-negative Matrix Factorisation (NMF) applied to a whole-corpus TF-IDF representation. This algorithm tries to discover a family of topics that best explains the word patterns across the text.
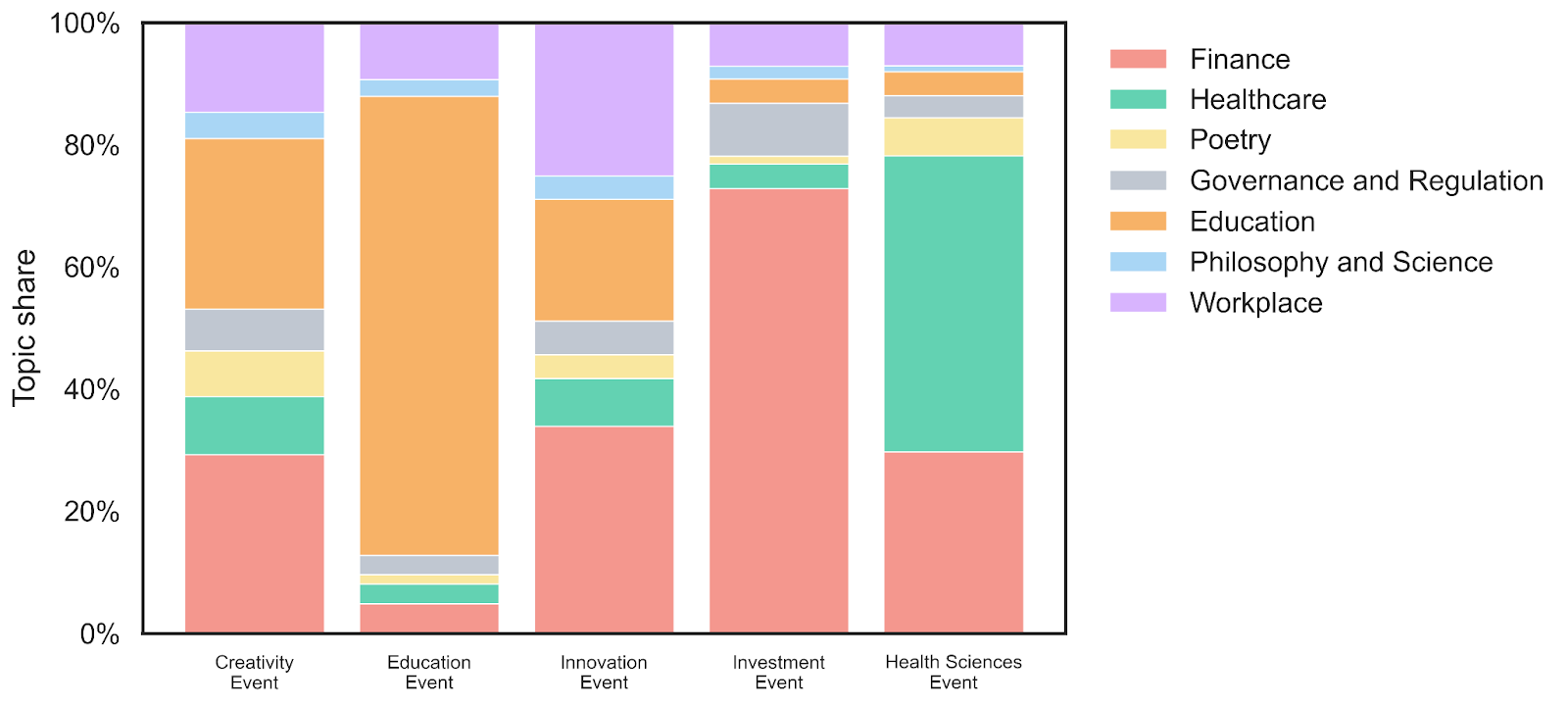
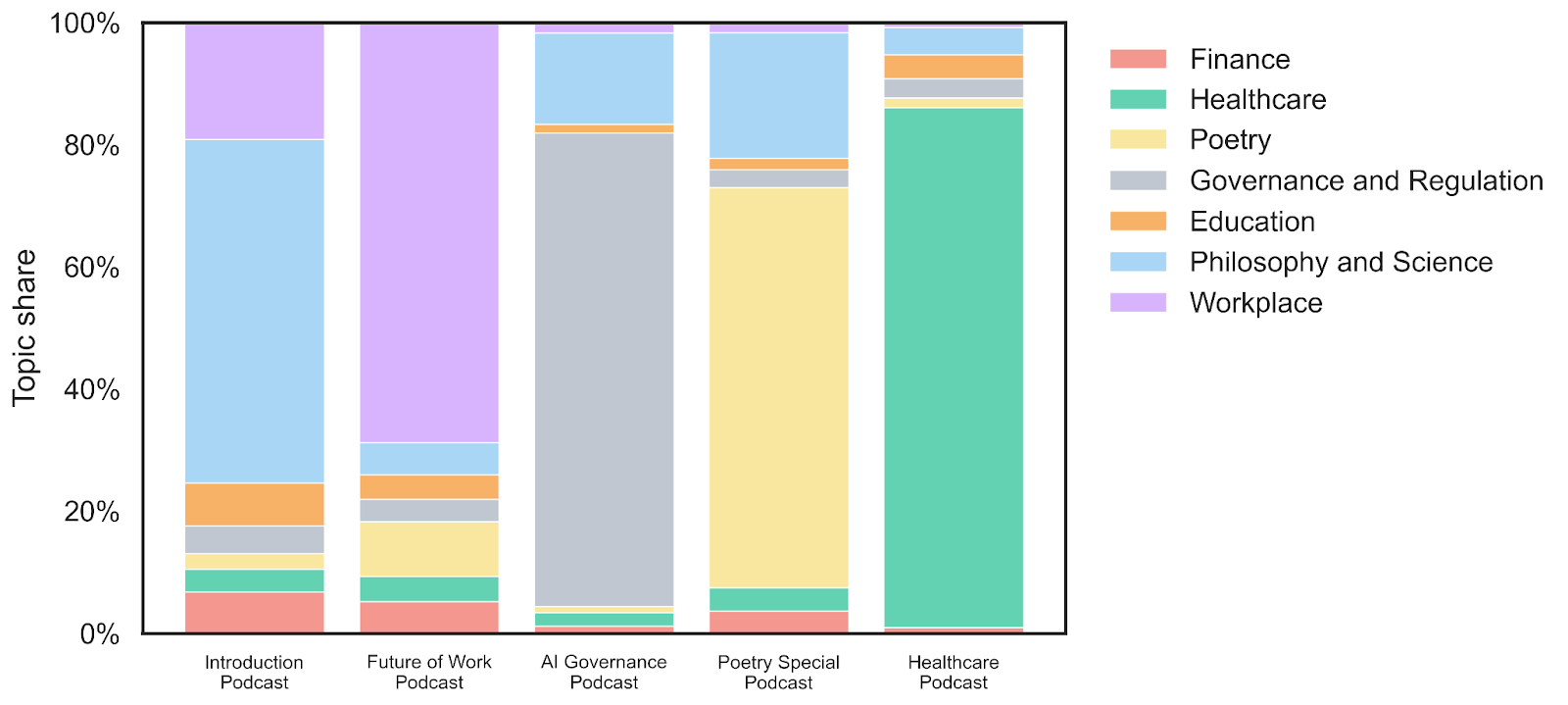
The model settled on seven topics: Finance, Healthcare, Poetry, Governance and Regulation, Education, Philosophy and Science, and Workplace. What is striking is how neatly most of these align with individual events or episodes. Healthcare chunks cluster in the healthcare transcripts, education in the Education Event, and poetry almost exclusively in the Poetry Special. The algorithm had no prior knowledge of which transcript was which; it found these groupings from the word patterns alone.
But the really interesting findings are the cross-cutting patterns. For instance, the innovation event draws widely from a number of topics: the workplace, education, and finance in particular. In fact, the finance and workplace topics were important for multiple events, whilst philosophy and science appear more often in the podcasts. Nonetheless, I was intrigued that the algorithm saw fit to group Philosophy and Science together as a single topic! Perhaps it suggests that across the Conversations on AI events and podcasts, philosophical and scientific vocabulary tend to co-occur, perhaps reflecting the interdisciplinary character of the series itself.
A caveat is essential here. Topic models are exploratory tools, not oracles. The number of topics is chosen by the analyst, the labels are human interpretations of word clusters, and the boundaries between topics are fuzzy. Different preprocessing choices or a different number of topics could yield somewhat different results. These maps are suggestive, not definitive.
We can visualise the relationships between events using a topic-similarity network. Each point (or node) is a full transcript, and a line (or edge) connects two transcripts whose topic mixtures are sufficiently similar. Thicker connecting lines between events indicate more topic overlap between the events; the positions come from a force-directed (spring) layout that pulls similar nodes together for readability.
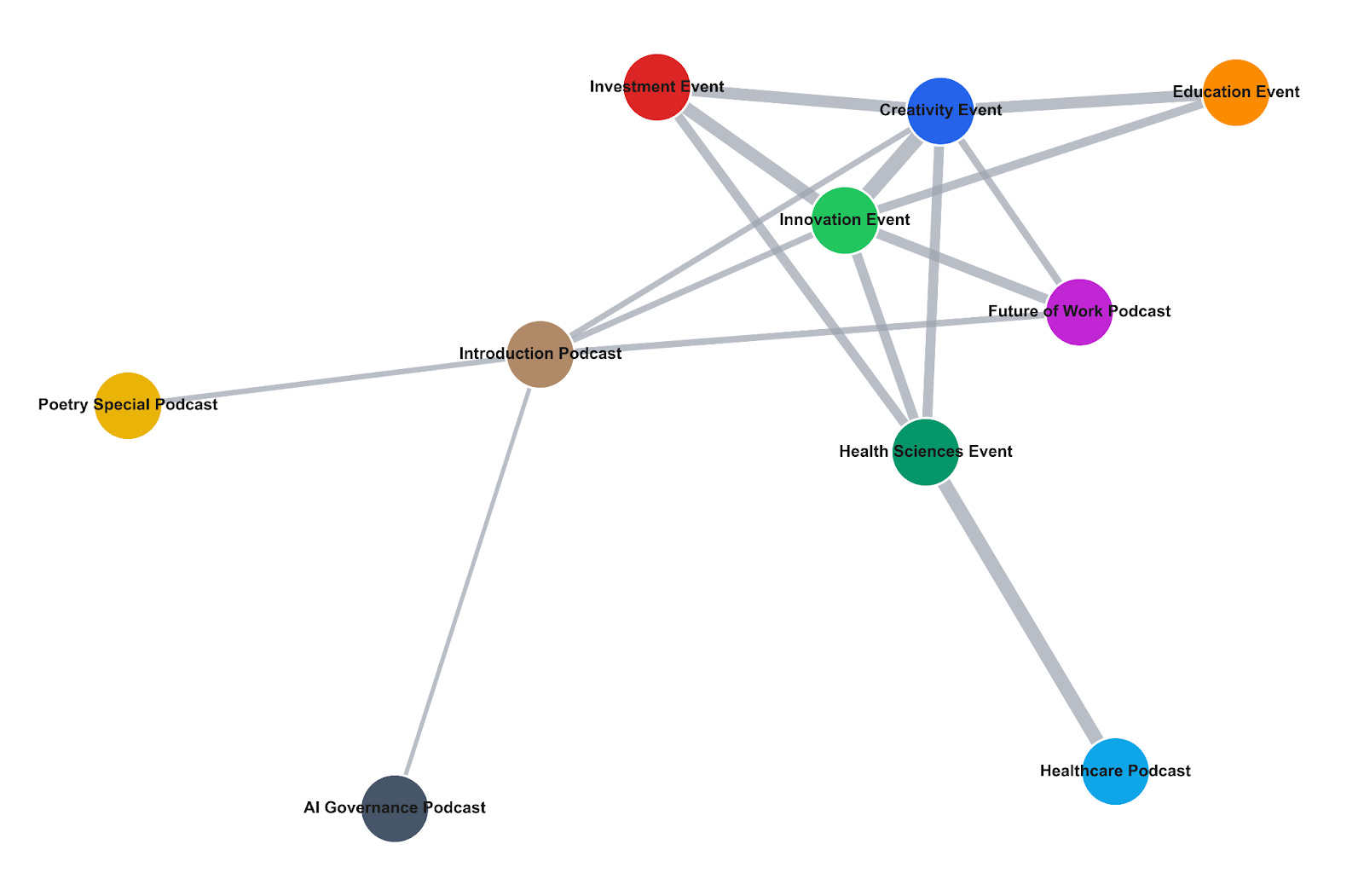
We see that the Innovation Event sits as a hub, connected to Investment, Creativity, Education, and more. The Introduction Podcast serves as a bridge, linking the more niche Poetry Special and AI Governance episodes to the broader cluster. The Healthcare Podcast and Health Sciences Event are connected to one another but sit at the periphery, their specialised medical vocabulary sets them somewhat apart from the rest of the corpus.
Mapping the Meaning
Finally, let’s consider how to map the overall “semantic content” of the corpus, i.e. which parts of different conversations use similar language. To do this, I found high-dimensional vectors of the most prominent words across the whole corpus and applied a dimensionality reduction technique called UMAP (Uniform Manifold Approximation and Projection). The result is sometimes called a latent space: a learned, low-dimensional representation of the high-dimensional structure in the original text. Each dot represents a chunk of text in the original transcript, and the coloured blobs show the footprint of each event or podcast in this shared space.
Below, we can see the landscape of conversational similarity. If two blobs overlap a lot, those conversations use similar language and framing. If a blob is tight and compact, it suggests that the conversation was focused. If it’s broad and diffuse, it suggests that the discussion ranged widely.
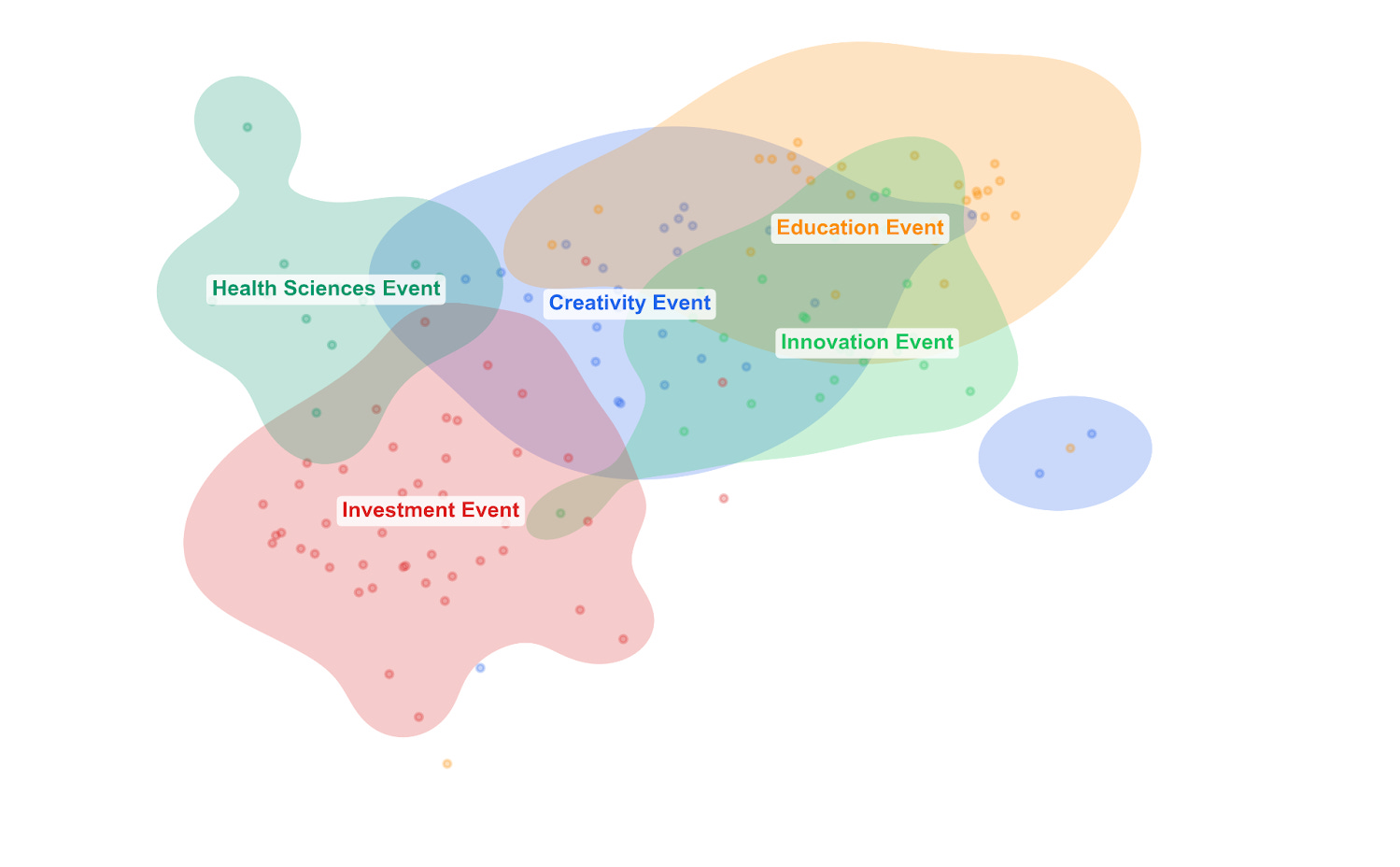
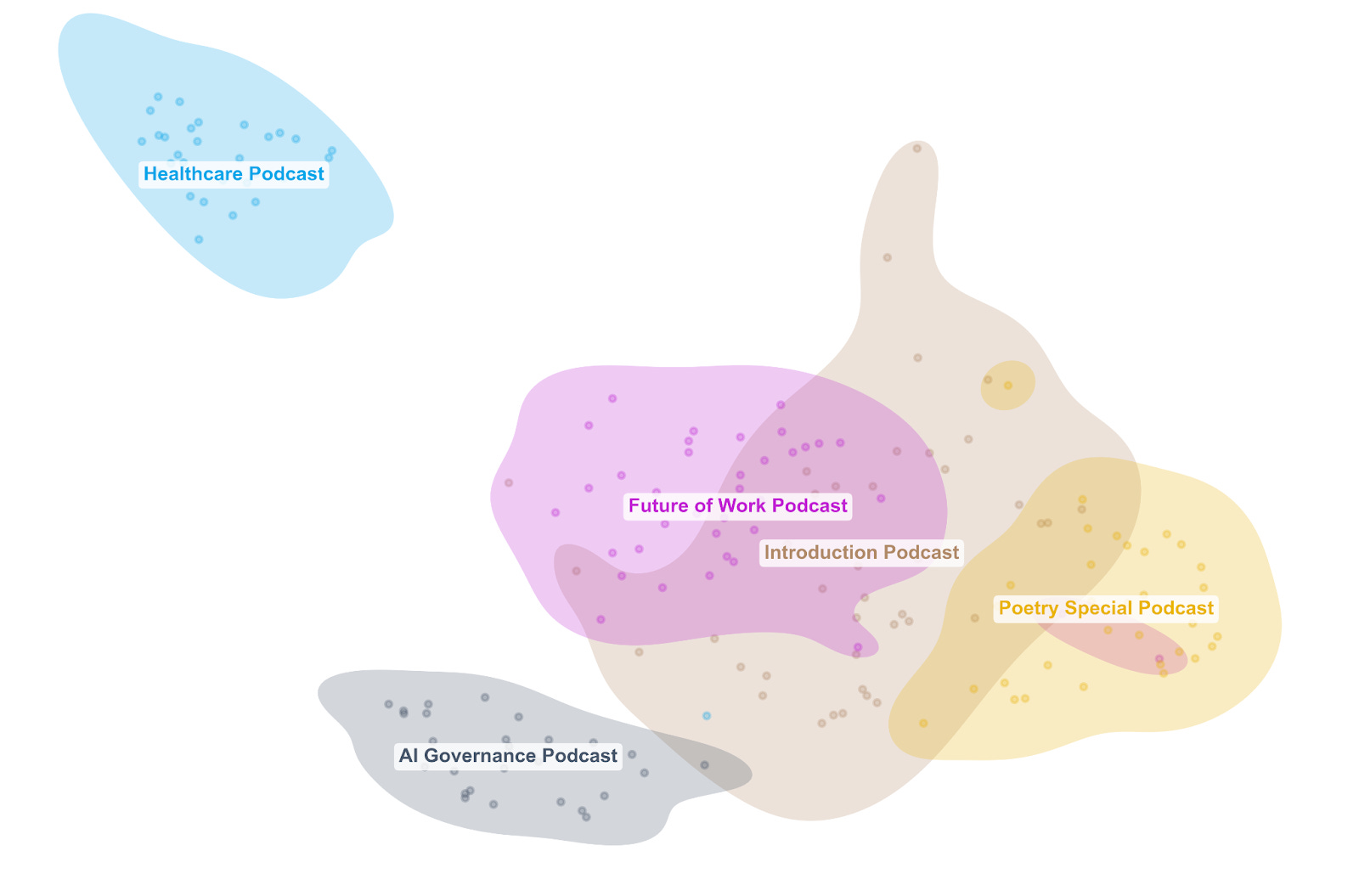
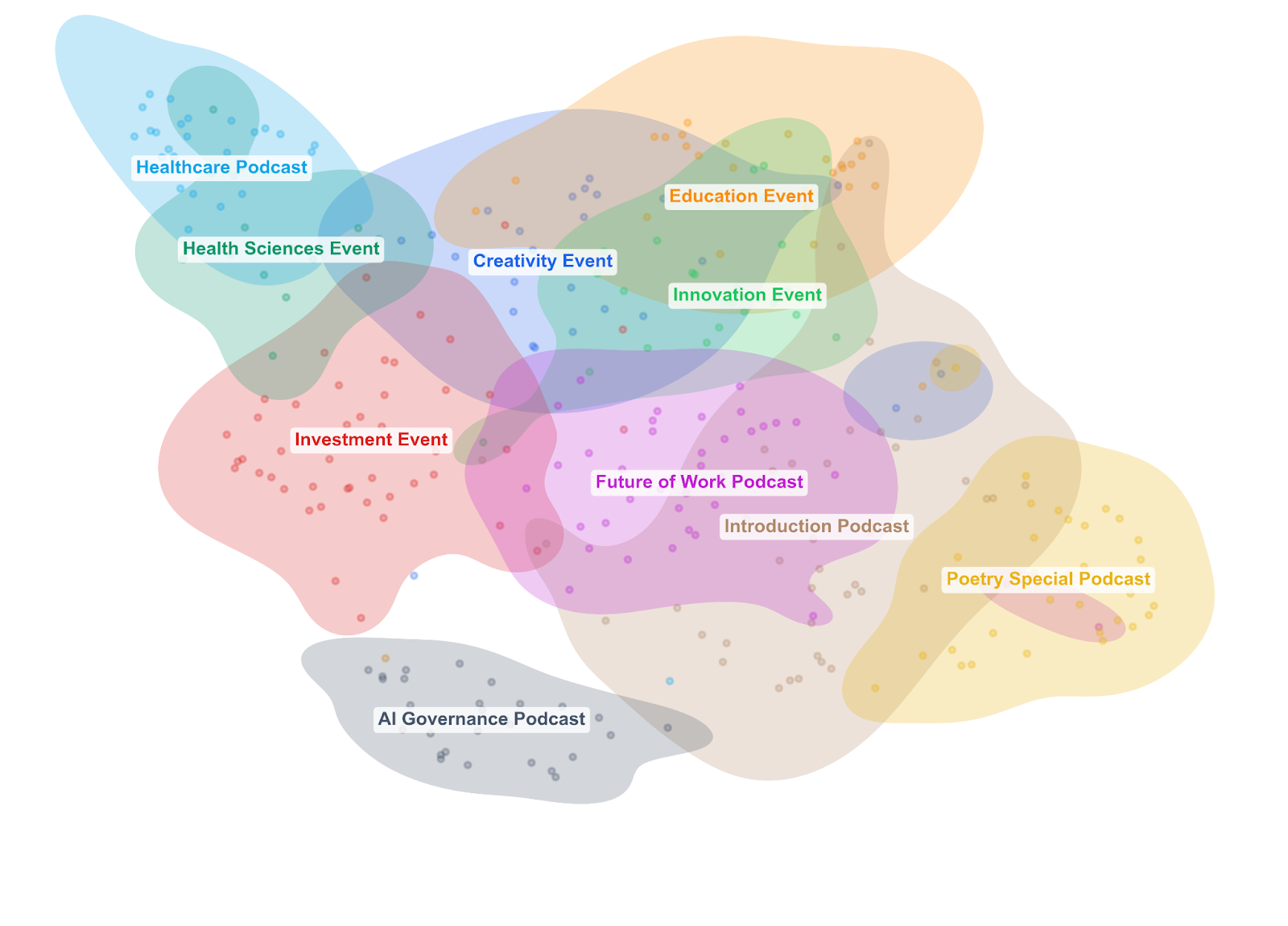
Again, we see that the Healthcare Podcast and Health Sciences Event cluster together in one corner: their language is distinctive and self-consistent. Several events overlap heavily in the centre, reflecting genuine shared vocabulary around tools, skills, values, and the future of work. The Investment Event spreads broadly, overlapping with several others but also stretching into
its own distinctive territory. The Poetry Special carves out its own region, overlapping partly with the introductory podcast, which, true to its broad scene-setting nature, sprawls across a wide area, overlapping with multiple other conversations.
Maps, not the territory
Every technique applied here produces a kind of map: a compressed, simplified representation that captures some patterns or features in these rich, complex conversations. Each map highlights different things: distinctive vocabularies, sentiment, topic structures and semantic relationships. Ultimately, what this kind of computational analysis can do is offer perspectives that complement human reading, highlighting patterns that would be hard to spot by eye alone. It can surface surprises. But it is still up to us to decide how to interpret them.
In other words, none of these maps can show us the territory. There is always more in the original conversations than any algorithm can capture: the tone of a speaker’s voice, the nuances of a particularly apt point, the moment when a panellist changes someone’s mind, the non-verbal cues which we cannot record. So whilst it’s endlessly interesting to try different models and methods, none of these can substitute coming to the events themselves!
Finally, what does all this tell us about Conversations on AI as a series? Taken together, the picture is of a genuinely interconnected set of discussions. These are not ten siloed talks that happen to share a brand name. Topics bleed across events, the Innovation Event acts as a thematic crossroads, and concerns about ethics, work, and human values surface in conversations ostensibly about investment, creativity, and healthcare alike. The series seems to be doing what it sets out to do: bringing different communities into a shared conversation.
Another note from the editors: The Conversations on AI event series was founded and is sustained by alumni from Northeastern University London’s MA programme in Philosophy and AI, together with faculty members from Philosophy. Click here to find out more about the programme. New applications are welcome.